28 Aug 2014
There are a lot of music discovery apps on the market, yet sifting through
concert listings is anything but seamless. That's why Cyprus-based startup
Concertwith.me aims to make finding local concerts
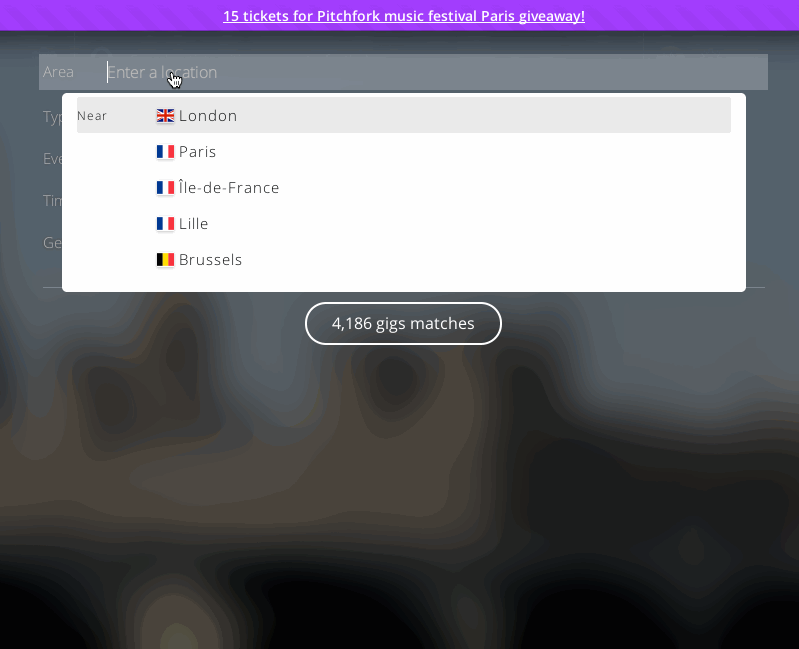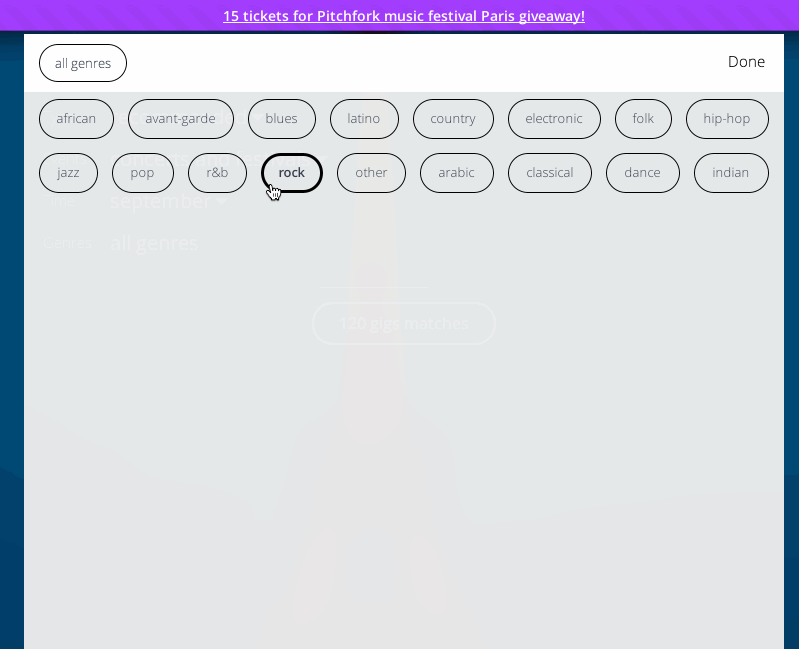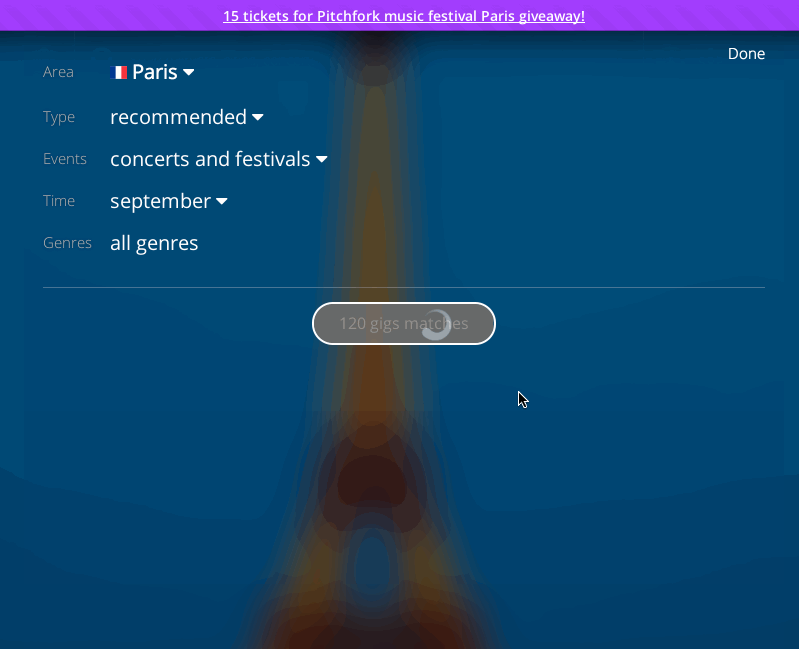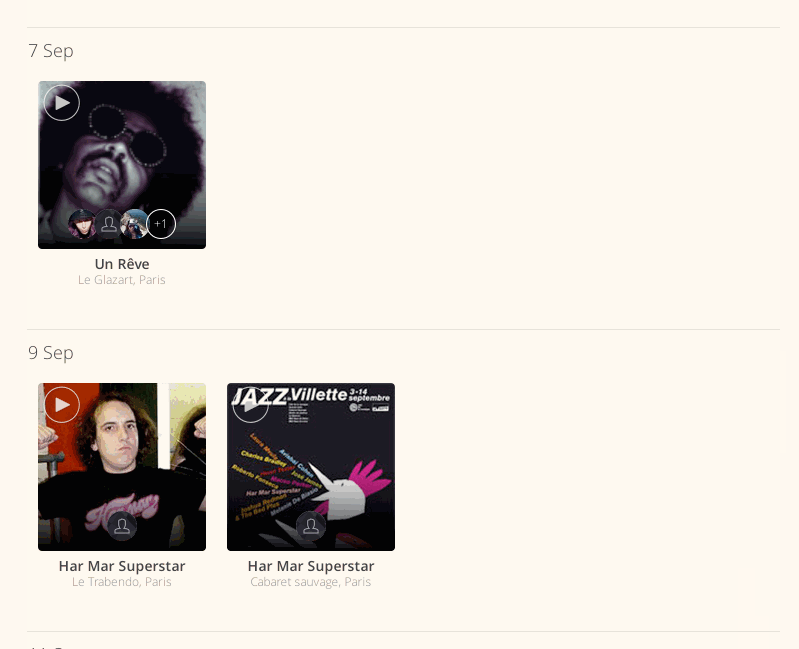
and festivals as intuitive as possible. Automatically showing upcoming events
in your area, the site offers personalized recommendations based on your
preferences and your Facebook friends' favorited music. Covering over 220,000
events globally, the site uses Algolia to offer meaningful results for
visitors who are also looking for something different.
Founder Vit Myshlaev admits that concert sites often share the same pool of
information. The differentiator is how that information is presented. "The
biggest advantage one can have is user experience," he explains. "There's
information out there, but do users find it? The reason that people don't go
to cool concerts is that they still don't know about them!"
As an example, he showed me one of the largest live music discovery sites on
the web. Searching for an artist required navigating a convoluted maze of
links before pulling up irrelevant results. "Users have to type in queries
without autocomplete, typo-tolerance, or internationalization. They have to
scroll through a long list of answers and click on paginated links. That's not
what people want in 2014," said Myshlaev.
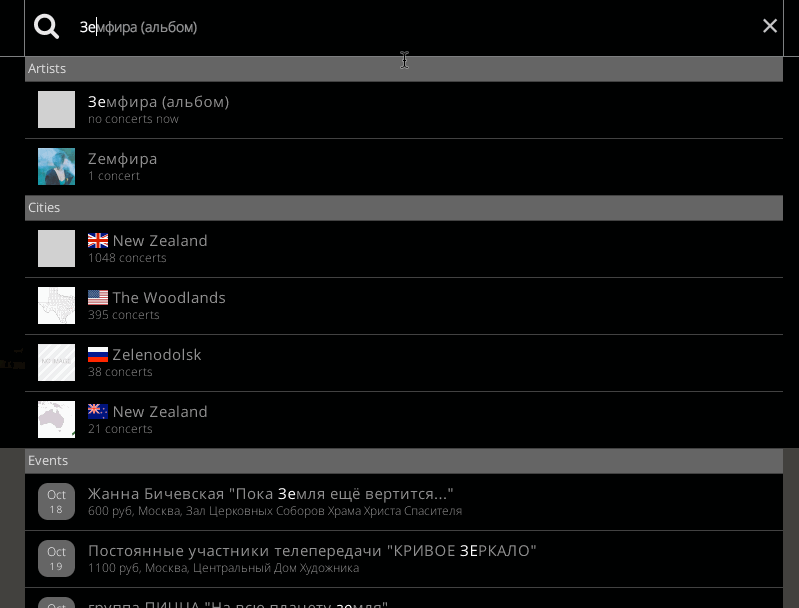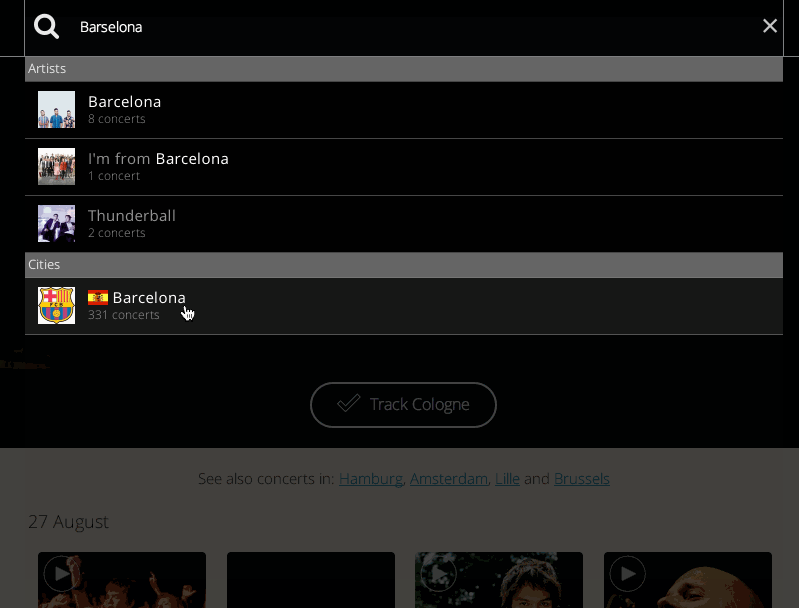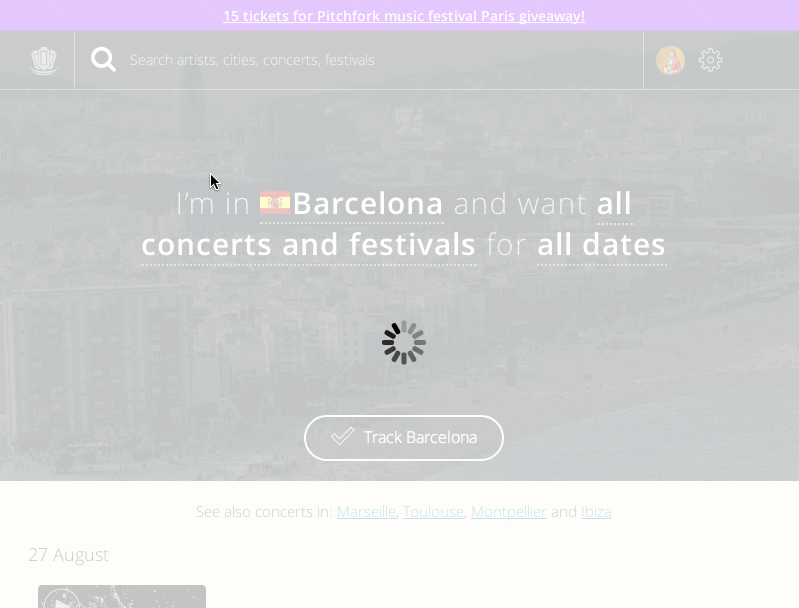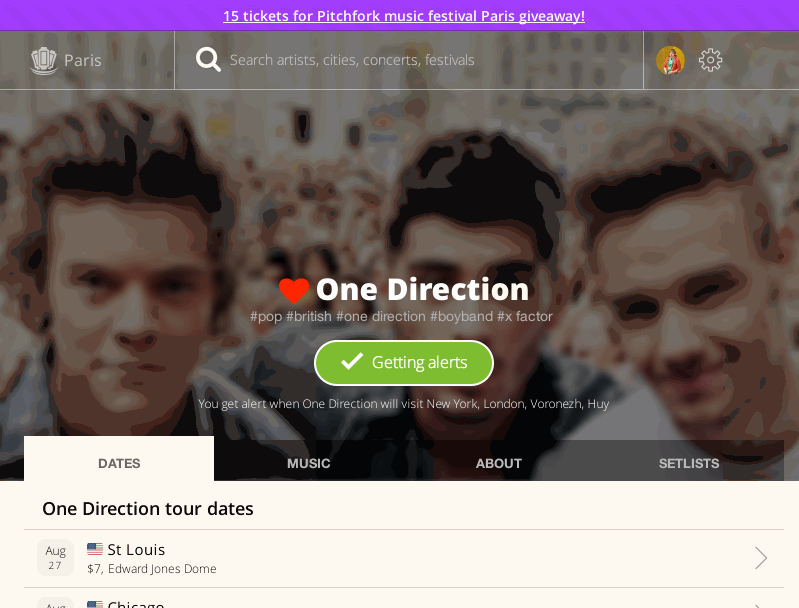
To simplify search and make the results more relevant, Concertwith.me used our
API. "We got a lot of user feedback for natural search," Myshlaev wrote. Now
visitors can search for artists and concerts instantly. With large user bases
in the United States, Germany, France, Spain, Italy, Russia and Poland,
Concertwith.me also benefits from Algolia's multi-lingual search
feature. "We've localized our app
to many countries. For example, you can search in Russian or for artists that
are Russian, and results will still come up," says Myshlaev.
For users with a less targeted idea of what they're looking for,
Concertwith.me implemented structured search via
faceting. "We also realized
that some visitors don't know what they want. Algolia search helps them find
answers to questions like, Where will my favorite artist perform? How much do
tickets cost? Are there any upcoming shows?"
Concertwith.me's goal is to reduce informational noise so that users can find
and discover music as soon as possible. The start up experimented with a
number of other search technologies before reading an article about us on
Intercom.io, which
inspired Myshlaev. "When I saw what Algolia could do, I knew that this was the
competitive edge I was looking for."
Want to build a search bar with multi-category auto-completion like Concertwith.me? Learn how through our tutorial.
21 Aug 2014
When one thinks of expense reporting, speed is far from the first descriptor
that comes to mind. Companies spend a substantial amount of time tracking
expenses, while employees linger in paperwork purgatory, wondering when they
will be reimbursed for their work-related charges. That's why Abacus has made
it their mission to simplify expense management so that it occurs in real
time. Their creative implementation of Algolia helps make it happen.
Abacus is a mobile and desktop application that allows small businesses to
track and verify expenses on the go. Employees can upload a photo of their
receipt on the mobile app, and Abacus takes care of the rest. "For each
expense, we have a lot of data. We have the person who expensed it, the amount
of the expense, the time, and where it took place. We also have a lot of
metadata. For example, if you went out to breakfast, we pull in the name of
the restaurant, the address, the URL of the merchant. There's tags and
categories and so on," explains Ted Power, Co-Founder of Abacus. "And we
wanted to make all of that searchable."
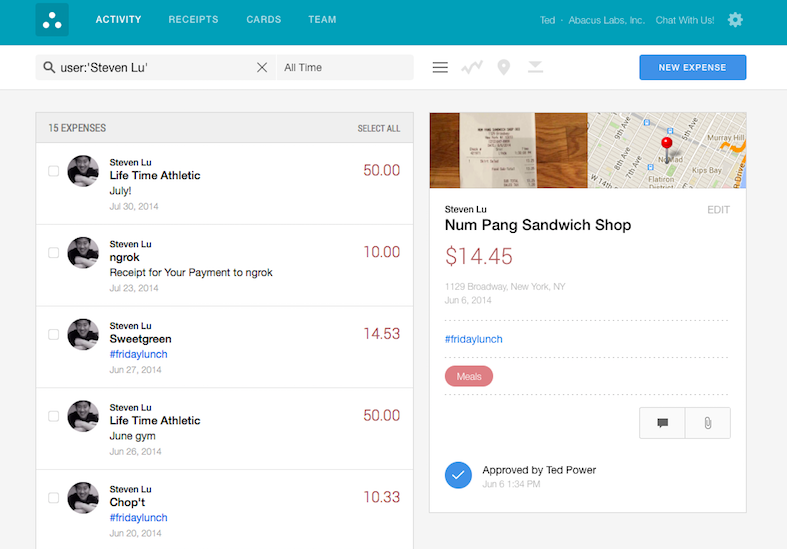
To make all of that data accessible and interpretable for a financial manager,
Abacus turned to our API. "Algolia made it super easy for us to get faceted,
advanced search options. If you are the finance person at your company, you
can basically say 'Show me all of the expenses over $50,' or 'Show me all the
expenses that don't have a receipt.' You can look at expenses for one person
or one category, like travel. You can even pivot off of 8 of these different
things. Algolia makes it super easy to do," says Power. This accelerates the
process of expense verification and approval. "It's good search. We have tags
like 'car rental' on auto-complete, for example. That's all Algolia."
Power adds that a "great implementation experience" was especially beneficial
for the start up. "It's the kind of thing that would have taken ages to build
from scratch." Co-Founder Joshua Halickman chimed in: "Being able to get up
and off the ground really quickly was great. In general, I love the speed.
Crazy fast. Really nice."

_Images courtesy of Abacus. Learn more [on their
website._]3
11 Jul 2014
The following post is an interview of Vincent Paulin, R&D Manager at A Little
Market (recently acquired by Etsy).
As a fast growing ecommerce site for handmade goods in France, A Little Market
has seen its marketplace grow from a few thousand to over 2 million products
in just 5 years. With 90,000 designers and artisans using A Little Market
marketplace to buy, sell and collaborate, search quickly became a major part
of their ecommerce strategy and user experience.
What did you have in place as a search solution?
"We implemented a Solr based search 5 years ago and had been trying to tweak
it to fit our growing needs. We had selected this system for its flexibility,
however, over time, that flexibility translated into constant maintenance,
modifications and lower relevance in our search results.
Then we investigated Elasticsearch. It is complex, yet powerful. As I was
diving deeper into Elasticsearch I realized that I could quickly gain an "ok"
search experience; however, a powerful search experience would mean investing
more time than we had to configure it. Then I did a little math: learning the
platform would take a few weeks, configuring servers - a few days, and
configuring and tuning semantic search perfectly - several months.
Then we found Algolia. We only had 3 months and knew Algolia would be much
easier to implement, so we A/B tested everything to see how it would impact
the search experience.
Can you tell us more about your integration process?
The first thing we wanted to get done was to reference all the shops and our
best searches to make an autosuggest widget. Building this autosuggest with a
basic configuration took us 2 days.
Then we built an automatic task to aggregate shops and best searches every day
and configure Algolia indices. We also took on the task to create the front
javascript plugin. With the Algolia documentation and the examples on Github
it took us less than 1 hour.
The results of this first test were very encouraging. With around 500k
requests per day, the response time was about 4 milliseconds on average and we
saw the conversion rate multiplied by 3 compared to the previous conversion
rate with a search bar with "no suggest". For A Little Mercerie, another
marketplace we manage, the improvement was about 4 times greater.
After this first test, we were ready to fully commit to Algolia for our whole
search experience. The first step was to create a script to index our entire
product database in Algolia. This was easy to do with batch insert in Algolia
indices. We selected some attributes of our products such as the title,
categories, materials and colors to be indexed. That was a first try. We
wanted it to be quick and simple.
With the help of the open source demo code we developed a full JS sandbox
which can display paginated results with faceting to show the progress to the
team. In less than a week, we had a fully working sandbox and the results
were promising. Our query time averaged less than 20 milliseconds on 2
millions records. With confidence we started to upgrade the algorithm on
Algolia, test it, again and again, adding some attributes to index such as
specific events (christmas, valentine's day), custom tags, etc.
In addition, we implemented sorted results. They are really relevant with the
new numeric ranking option in settings. At that step we were able to sort
results by price, date, etc. You must create a specific index for each
specific ranking you need. We also created a different index for each
language (French and Italian) and took this opportunity to do the same across
our other websites, alittlemercerie.com and alittleepicerie.com.
To do this we created a custom API which abstracts the use of any kind of
search engine for all API clients. We end up losing the real-time search but
we need that for now in order to abstract everything and to collect data
before sending the results.
The next step was to erase the "no results" pages. For that, we were
progressively adding the last words of the query as optional words until we
had somes results.We never set as optional all the user queries. We set at
least the first word or the first two words.
When search was ready, we still had plenty of time left to implement it on our
clients' applications. We took more time than was needed to implement Algolia.
The speed of iteration with the Algolia API enables us to test everything in a
much shorter timeframe.
How has Algolia's API helped search on A Little Market?
We are now able to answer more than 500/1000 requests per minute and we add
6000 new products every day to the search engine while over 3000 are removed,
in real time.
After this integration of the Algolia API, we saw an increase in our
conversion rate on search by 10%. This represents tens thousands of euros in
turnover per month for us. In a few weeks of work with one engineer, we had
replaced our main search engine for a better solution thanks to Algolia."
09 Jul 2014
When we developed the first version of Algolia Search, we put a lot of effort
into developing a data update API. It worked like this: You could send us a
modified version of your data as soon as the change appeared, even if it
concerned only a specific part of a record. For example, this batch of
information could be the updated price or number of reviews, and we would only
update this specific attribute in your index.
However, this initial plan did not take into account that most of our big
customers would not benefit from this API due to their existing
infrastructure. If you had not planned to catch all updates in your
architecture, or if you were not using a framework like Ruby on Rails, it
could be very difficult to even have a notification for any of these updates.
The solution in this case was to use a batch update on a regular basis. It was
a good method to use if you didn't want to change a single line of code in
your existing infrastructure, but the batch update was far from a cure-all.
The problem of batch update
There are two main ways to perform a batch update on a regular basis:
- Scan your database and update all objects. This method is good if you have no delete operation, but if some data are removed from your database, you will need to perform an extra check to handle delete, which can be very slow.
- Clear the content of the index and import all your objects. With this method, you ensure that your index is well synchronized with your database. However, if you receive queries during the import, you will return partial results. If interrupted, the whole rescan could break your relevance or your service.
So the two approaches are somewhat buggy and dangerous.
Another approach: build a new index with another name
Since our API allows the creation of a new index with a different name, you
could have made your batch import in a new index. Afterward, you would just
need to update your front end to send queries to this new index.
Since all indexing jobs are done asynchronously, we first need to check that
an indexing job is finished. In order to do that, we return an integer (called
TaskID) that allows you to check if an update job is applied. Thus, you just
have to use the API to check that the job is indexed.
But then a problem arises with mobile applications: You cannot change the
index name of an application as easily, since most of the time, it is a
constant in the application code. And even for a website, it means that the
batch will need to inform your frontend that the index name is different. This
can be complex.
The elegant solution: move operation
To solve these problems, we implemented a command that is well known on file
systems: move. You can move your new index on the old one, and this will
atomically update the content of the old index with the content of the new
one. With this new approach, you can solve all the previous update problems
with one simple procedure. Here's how you would update an index called
"MyIndex":
- Initialize an index "MyIndex.tmp"
- Scan your database and import all your data in "MyIndex.tmp"
- Move "MyIndex.tmp in "MyIndex"
You don't have to do any modification on your backend to catch modifications,
nor do you need to change the index name on the frontend. Even better, you
don't need to check the indexing status with our TaskID system since the
"move" operation will simply be queued after all "adds". All queries will go
to the new index when it is ready.
The beauty of the move command
This command is so elegant that even customers who had been sending us
realtime updates via our updates API have decided to use this batch update on
a regular basis. The move command is a good way to ensure that there are no
bugs in your update code, nor divergence between your database and Algolia.
This operation is supported in our twelve API Clients. We go even further in
our Ruby on Rails integration: You need only use the 'reindex' command
(introduced in 1.10.5) to automatically build a new temporary index and move
it on top of the existing one.
The move command is an example of how we try to simplify the life of
developers. If you see any other way we can help you, let us know and we'll do
our best to remove your pain!
05 Jun 2014
Since the first SaaS IPO by salesforce.com, the
SaaS (Software as a Service) model has boomed in the last decade to become a
global market that is worth billions today. It has taken a long way and a lot
of evangelisation to get there.
Before salesforce.com and the other SaaS
pioneers succeeded at making SaaS a standard model, the IT departments were
clear: the infrastructure as well as the whole stack had to be behind their
walls. Since then, mindsets have shifted with the cloud revolution, and you
can now find several softwares such as Box, Jive or Workday used by a lot of
Fortune 500 companies and millions of SMBs and startups.
Everything is now going SaaS, even core product components such as internal
search. This new generation of SaaS products is facing the same misperceptions
their peers faced years ago. So today, we wanted to dig into the
misperceptions about search as a service in general.
Hosting your search is way more complex and expensive than you may think
Some people prefer to go on-premises as they only pay for the raw resource,
especially if they choose to run open source software on it. By doing this,
they believe they can skip the margin layer in the price of the SaaS
solutions. The problem is that this view highly under-estimates the Total Cost
of Ownership (TCO) of the final solution.
Here are some reasons why hosting your own search engine can get extremely
complex & expensive:
Hardware selection
A search engine has the particularity of being very IO (indexing), RAM
(search) and CPU (indexing + search) intensive. If you want to host it
yourself, you need to make sure your hardware is well sized for the kind of
search you will be handling. We often see companies that run on under-sized
EC2 instances to host their search engine are simply unable to add more
resource-consuming features (faceting, spellchecking, auto-completion).
Selecting the right instance is more difficult than it seems, and you'll need
to review your copy if your dataset, feature list or queries per second (QPS)
change. Elasticity is not only about adding more servers, but is also about
being able to add end-users features. Each Algolia cluster is backed by 3
high-end bare metal servers with at least the following hardware
configuration:
- CPU: Intel Xeon (E5-1650v2) 6c/12t 3,5 GHz+/3,9 GHz+
- RAM: 128GB DDR3 ECC 1600MHz
- Disk: 1.2TB SSD (via 3 or 4 high-durability SSD disks in RAID-0)
This configuration is key to provide instant and realtime search, answering
queries in <10ms.
Server configuration
It is a general perception of many technical people that server configuration
is easy: after all it should just be a matter of selecting the right EC2
Amazon Machine Image (AMI) + a puppet/chef configuration, right?
Unfortunately, this isn't the case for a search engine. Nearly all AMIs
contain standard kernel settings that are okay if you have low traffic, but a
nightmare as soon as your traffic gets heavier. We've been working with
search engines for the last 10 years, and we still discover kernel/hardware
corner cases every month! To give you a taste of some heavyweight issues
you'll encounter, check out the following bullet points:
- IO: Default kernel settings are NOT optimized for SSDs!!! For example, Linux's I/O scheduler is configured to merge some I/Os to reduce the hard-drive latency while seeking the disk sectors: non-sense on SSD and slowing the overall server performance.
- Memory: The kernel caches a lot, and that's cool... most of the time. When you write data on the disk, it will actually be written in the RAM and flushed to disk later by the pdflush process. There are some advanced kernel parameters that allow configuration. vm.dirtybackgroundratio is one of them: it configures the maximum percentage of memory that can be "dirty" (in cache) before it is written on the disk. In other words, if you have 128GB of RAM, and you are using the default value of 10% for dirtybackgroundratio, the system will only flush the cache when it reaches 12GB!!!! Flushing such bursts of writes will slow down your entire system (even on SSD), killing the speed of all searches & reads. Read more.
- Network: When calling the listen function in BSD and POSIX sockets, an argument called the backlog is accepted. The backlog argument defines the maximum length of the queue of pending connections for sockfd. If the backlog argument is higher than the value in net.core.somaxconn, it is silently truncated to that value. The default value is 128 which is way too low! If a connection request arrives when the queue is full, the client may receive an error with an indication of ECONNREFUSED. Read more & even more.
We've been working hard to fine-tune such settings and it has allowed us to
handle today several thousands of search operations per second on one server.
Deployment & upgrades are complex
Upgrading software is one of the main reasons of service outages. It should be
fully automated and capable of rolling back in case of a deployment failure.
If you want to have a safe deployment, you would also need a pre-production
setup that duplicates your production's setup to validate a new deployment, as
well as an A/B test with a part of your traffic. Obviously, such setup
requires additional servers. At Algolia, we have test and pre-production
servers allowing us to validate every deployment before upgrading your
production cluster. Each time a feature is added or a bug is fixed on the
engine, all of our clusters are updated so that everyone benefits from the
upgrade.
Toolbox vs features
On-premises solutions were not built to be exposed as a public service: you
always need to build extra layers on top of it. And even if these solutions
have plenty of APIs and low-level features, turning them into end-user
features requires time, resources and a lot of engineering (more than just a
full-stack developer!). You may need to re-develop:
- ***Auto-completion:* to suggest best products/queries directly from the search bar while handling security & business filters (not only suggesting popular entries);
- Instant-Faceting: to provide realtime faceting refreshed at each keystroke;
- ***Multi-datacenter replication:* synchronize your data across multiple instances and route the queries to the right datacenter to ensure the best search performance all around the world;
- Queries analytics: to get valuable information on what and how people search;
- Monitoring: To track in realtime the state of your servers, the storage you use, the available memory, the performance of your service, etc.
On-premises is not as secure as one might think
Securing a search engine is very complex and if you chose to do it yourself,
you will face three main challenges:
- Controlling who can access your data: You probably have a model that requires permissions associated with your content. Search as a service providers offer packaged features to handle user based restrictions. For example you can generate an API Key that can only target specific indexes. Most on-premise search engines do not provide any access control feature.
- Protecting yourself against attacks: There are various attacks that your service can suffer from (denial of service, buffer overflow, access control weakness, code injection, etc.). API SaaS providers put a lot of effort into having the best possible security. For example API providers reacted the most quickly to the "HeartBleed" SSL vulnerability; It only took a few hours after disclosure for Twilio, Firebase and Algolia to fix the issue.
- Protecting yourself from unwarranted downloads: The search feature of your website can easily expose a way to grab all your data. Search as a service providers offer packaged features to help prevent this problem (rate limit, time-limited API Key, user-restricted API Key, etc.).
Mastering these three areas is difficult, and API providers are challenged
every day by their customers to provide a state-of-the-art level of security
in all of them. Reaching the same level of security with an on-premise
solution would simply require too much investment.
Search as a service is not reserved to simple use cases
People tend to believe that search as a service is only good for basic use
cases, which prevents developers from implementing fully featured search
experiences. The fact of the matter is that search as a service simply handles
all of the heavy lifting while keeping the flexibility to easily configure the
engine. Therefore it enables any developers, even front-end only developers,
to build complex instant search implementation with filters, faceting or geo-
search. For instance, feel free to take a look at
JadoPado, a customer who developed a fully featured
instant search for their e-commerce store. Because your solution runs inside
your walls once in production, you will need a dedicated team to constantly
track and fix the multiple issues you will encounter. Who would think of
having a team dedicated to ensuring their CRM software works fine? It makes no
sense if you use a SaaS software like most people do today. Why should it make
more sense for components such as search? All the heavy lifting and the
operational costs are now concentrated in the SaaS providers' hands, making it
eventually way more cost-efficient for you..



