What Caused Today's Search Performance Issues In Europe and Why It Will Not Happen Again
17 Mar 2014During a few hours on March 17th you may have noticed longer response times for some of the queries sent by your users.
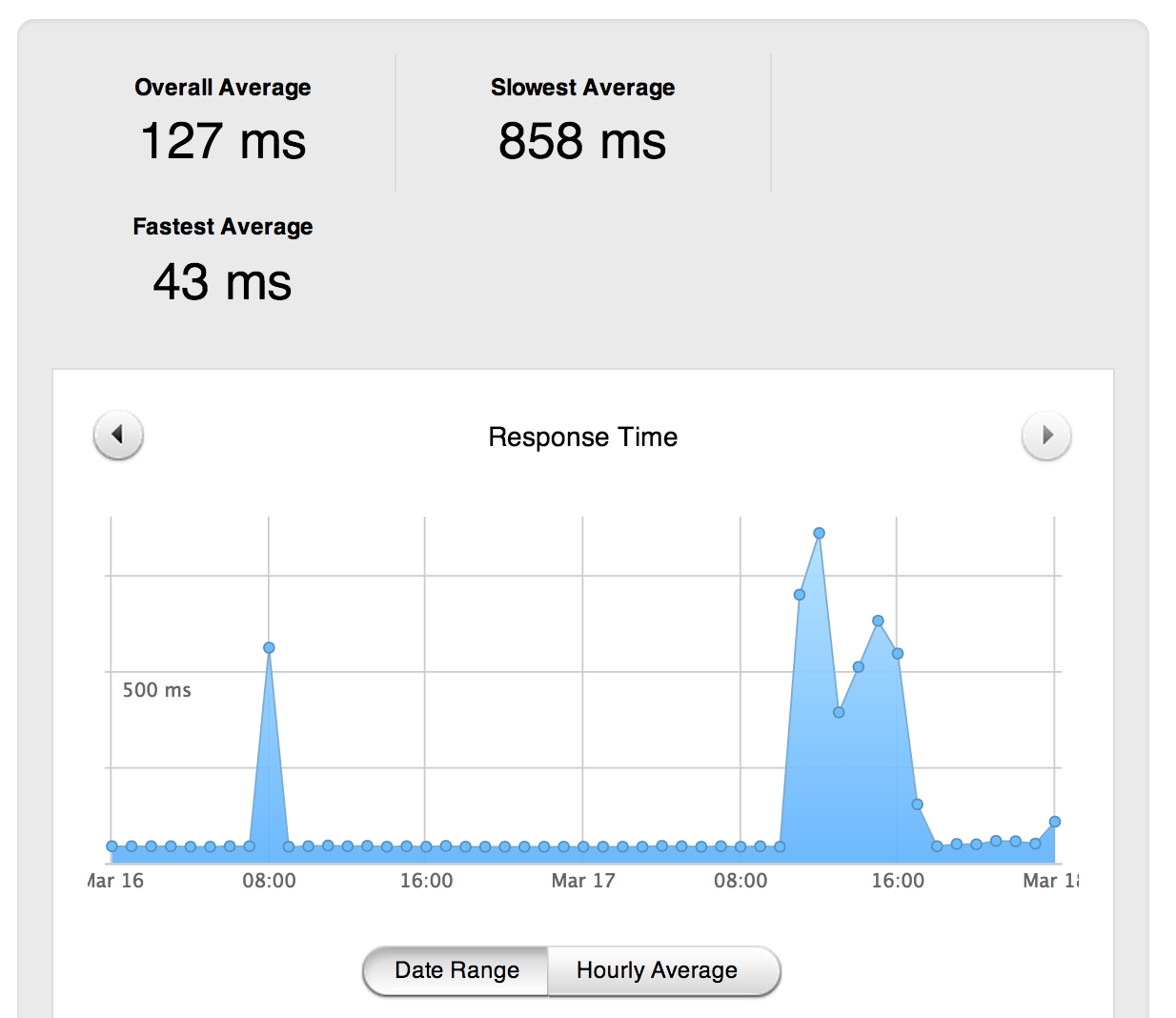
Average latency for one of our European clusters on March 17th
As you can see above, our slowest average response time (measured from the user's browser to our servers and back to the user's browser) on one of our European clusters peaked at 858ms. On a normal day, this peak is usually no higher than 55ms.
This was clearly not a normal behavior for our API, so we investigated.
How indexing and search calls share the resource
Each cluster handles two kinds of calls on our REST API: the ones to build and modify the indexes (Writes) and the ones to answer users' queries (Search). The resources of each cluster are shared between these two uses. As Write operations are far more expensive than Search calls, we designed our API so that indexing should never use more than 10% of these resources.
Up until now, we used to set a limitation on the rate of Writes per HTTP connection. There was no such limit for queries (Search); We simply limited Write calls to keep search quality. To avoid reaching the Write rate limit too quickly, we recommended users to Write by batching up to 1GB of operations per call, rather than sending them one by one. (A batch, for example, could be adding 1M products to an index on a single network call.) A loophole in this recommendation was the origin of yesterday's issues.
What happened yesterday is that on one of our European clusters, one customer pushed so many unbatched indexing calls from different HTTP connections that they massively outnumbered the search calls of the other users on the cluster.
This eventually slowed down the average response time for the queries on this cluster, impacting our usual search performance.
The Solution
As of today, we now set the rate limit of Writes per account and not per HTTP connection. It prevents anyone from using multiple connections to bypass this Write rate limit. This also implies that customers who want to push a lot of operations in a short time simply need to send their calls in batches.
How would you batch your calls? The explanation is in our documentation. See here for an example with our Ruby client: https://github.com/algolia /algoliasearch-client-ruby#batch-writes