25 Mar 2014
As you may probably know, we're using HipChat to build our live-help chat. If
you want to know more, go ahead and read our guest post on HipChat's
blog.
Algolia uses HipChat to
provide live customer service over chat.
18 Mar 2014
Edit: As suggested on Hacker
News, SHA256 is not secure, as
it allows a length extension attack. We have replaced it with HMAC-SHA256.
Instant is in our DNA, so our first priority was to build a search backend
that would be able to return relevant realtime search results in a few
milliseconds. However, the backend is just one variable in our realtime
equation. The response time perceived by the end user is the total lapse of
time between their first keystroke and the final display of their results.
Thus, with an extremely fast backend, solving this equation comes down to
optimising network latency. This is an issue we solve in two steps:
- First, we have datacenters in three different locations, allowing us to answer queries in North America, Europe and Asia in less than 100ms (including search computation).
- Second, to keep reducing this perceived latency, queries must be sent directly from the end users' browsers or mobile phones to our servers. To avoid intermediaries like your own servers, we offer a JavaScript client for websites and ObjC/Android/C# clients for mobile apps.
The security challenge of JavaScript
Using this client means that you need to include an API key in your JavaScript
(or mobile app) code. The first security issue with this approach is that this
key can be easily retrieved by anyone who simply looks at the code of the
page. This gives that person the potential to modify the content behind the
website/mobile application! To fix this problem, we provide search-only API
keys which protect your indexes from unauthorized modifications.
This was a first step and we've quickly had to solve two other security
issues:
- *Limiting the ability to crawl your data: *you may not want people to get all your data by continuous querying. The simple solution was to limit the number of API calls a user could perform in a given period of time. We implemented this by setting a rate limit per IP address. However, this approach is not acceptable if a lot of users are behind a global firewall, thus sharing one IP address. This is very likely for our corporate users.
- Securing access control: you may need to restrict the queries of a user to specific content. For example, you may have power users who should get access to more content than "regular" users. The easy way to do it is by using filters. The problem here with simple filters in your JavaScript code is that people can figure out how to modify these filters and get access to content they are not be supposed to see.
How we solve it altogether
Today, most websites and applications require people to create an account and
log in to access a personalized experience (think of CRM applications,
Facebook or even Netflix). We decided to use these user IDs to solve these two
issues by creating signed API keys. Let's say you have an API key with search
only permission and want to apply a filter on two groups of content (public OR
powerusersonly) for a specific user (id=42):
api_key=20ffce3fdbf036db955d67645bb2c993
query_filters=(public,power_users_only)
user_token=42
You can generate a secured API key in your backend that is defined by a hash
(HMAC SHA 256) of three elements:
secured_api_key=HMAC_SHA_256(api_key, query_filters + user_token)
secured_api_key=HMAC_SHA_256("20ffce3fdbf036db955d67645bb2c993", "(public,power_users_only)" + "42")
secured_api_key="3abb95c273455ce9b57c61ee5258ba44093f17022dd4bfb39a37e56bee7d24a5"
For example, if you are using rails, the code in your backend would be:
secured_key = Algolia.generate_secured_api_key('20ffce3fdbf036db955d67645bb2c993', '(public,power_users_only)', '42')
You can then initialize your JavaScript code with the secured API key and
associated information:
The user identifier (defined by SetUserToken) is used instead of the IP
address for the rate limit and the security filters (defined by
SetSecurityTags) are automatically applied to the query.
In practice, if a user wants to overstep her rights, she will need to modify
her security tags and figure out the new hash. Our backend checks if a query
is legit by computing all the possible hashes using all your available API
keys for the queried index, as well as the security tags defined in the query
and the user identifier (if set). If there is no match between the hash of
the query and the ones we computed, we will return a permission denied (403).
Don't worry, reverse-engineering the original API key using brute-force would
require years and thousands of
core.
You may want to apply security filters without limiting the rate of queries,
so if you don't need both of these features, you can use only one.
We launched this new feature a few weeks ago and we have received very good
feedback so far. Our customers don't need to choose anymore between security
and realtime search. If you see any way to improve this approach, we would
love to hear your feedback!
17 Mar 2014
During a few hours on March 17th you may have noticed longer response times
for some of the queries sent by your users.
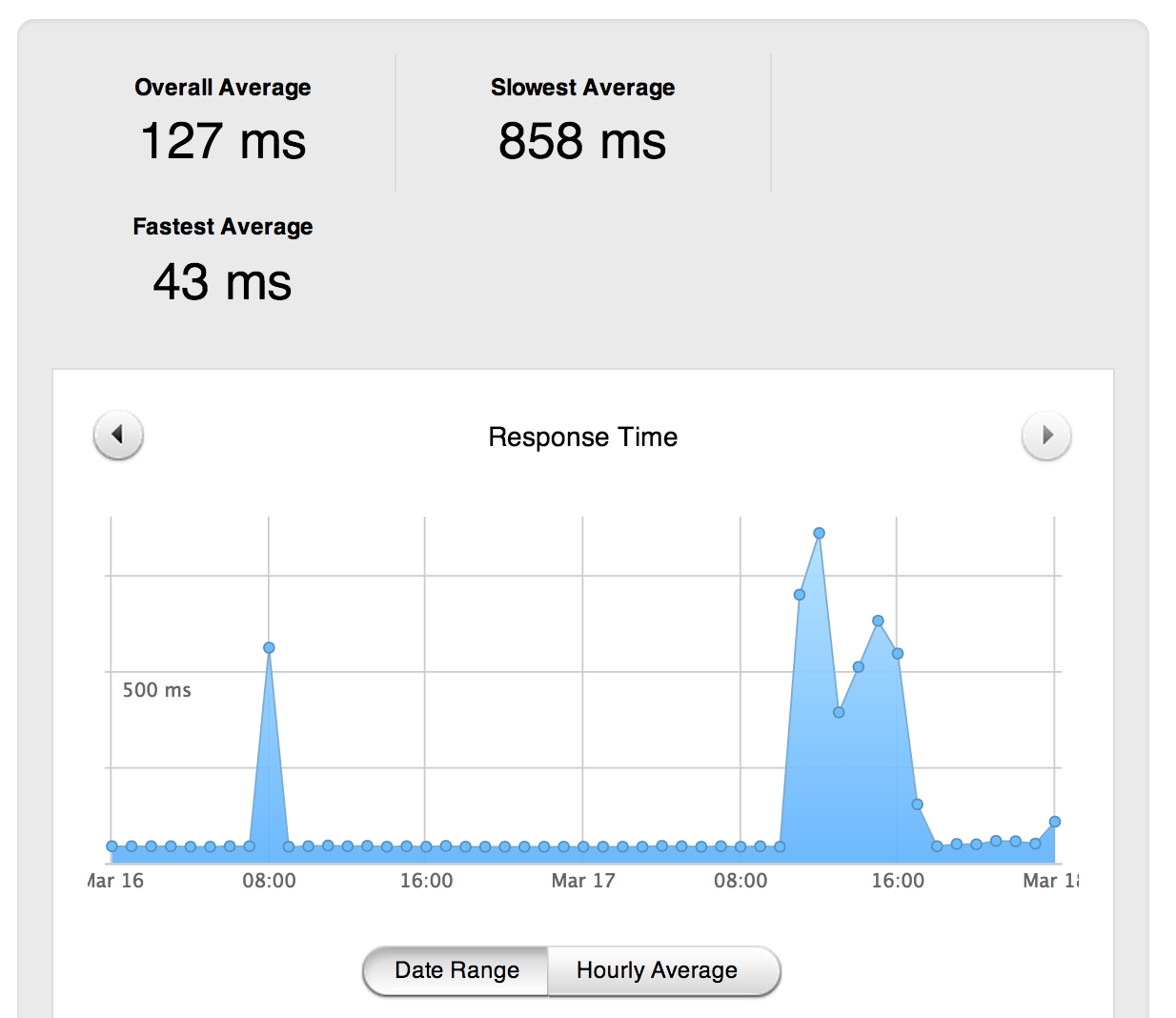
Average latency for one of our European clusters on March 17th
As you can see above, our slowest average response time (measured from the
user's browser to our servers and back to the user's browser) on one of our
European clusters peaked at 858ms. On a normal day, this peak is usually no
higher than 55ms.
This was clearly not a normal behavior for our API, so we investigated.
How indexing and search calls share the resource
Each cluster handles two kinds of calls on our REST API: the ones to build and
modify the indexes (Writes) and the ones to answer users' queries (Search).
The resources of each cluster are shared between these two uses. As Write
operations are far more expensive than Search calls, we designed our API so
that indexing should never use more than 10% of these resources.
Up until now, we used to set a limitation on the rate of Writes per HTTP
connection. There was no such limit for queries (Search); We simply limited
Write calls to keep search quality. To avoid reaching the Write rate limit too
quickly, we recommended users to Write by batching up to 1GB of operations per
call, rather than sending them one by one. (A batch, for example, could be
adding 1M products to an index on a single network call.) A loophole in this
recommendation was the origin of yesterday's issues.
What happened yesterday is that on one of our European clusters, one customer
pushed so many unbatched indexing calls from different HTTP connections that
they massively outnumbered the search calls of the other users on the cluster.
This eventually slowed down the average response time for the queries on this
cluster, impacting our usual search performance.
The Solution
As of today, we now set the rate limit of Writes per account and not per
HTTP connection. It prevents anyone from using multiple connections to bypass
this Write rate limit. This also implies that customers who want to push a lot
of operations in a short time simply need to send their calls in batches.
How would you batch your calls? The explanation is in our documentation. See
here for an example with our Ruby client: https://github.com/algolia
/algoliasearch-client-ruby#batch-writes
15 Mar 2014
We launched the first beta of our Heroku add-on in October 2013 and are now
happy to announce its general availability!
During the beta period we received excellent feedback (and some bug reports!)
that helped us improve our integration. We are now fully ready to serve
production on both Heroku datacenters. If you were part of our beta program,
we will contact you shortly to invite you to migrate to a standard plan.
You can directly install it from our Heroku add-on
page and as ever, please let us
know if you have any feedback!
14 Mar 2014
One of the terrific advantages of building a SaaS company is that your clients
can be anywhere in the world. We now have customers in more than 15 different
countries distributed across South America, Europe, Africa, and, of course,
North America. We feel incredibly lucky to have so many international
customers trusting us with their search.
Language support is one of the key factors that enabled us to enter these
markets. Since the beginning, we wanted to support every language used on the
Internet. To back our vision with action, we developed a very good support of
Asian languages over time. As an example, we are able to automatically
retrieve results in Traditional Chinese when the query is in Simplified
Chinese (or vice-versa). You simply need to add objects in Chinese, Japanese
or Korean, and we handle the language processing for you.
Despite the fact that we could process Asian languages well, we didn't plan to
open an Asian datacenter so early, mainly because we thought the API as a
service market was less mature in Asia than in the US or Europe. But we were
surprised when an article on 36kr.com
gave us dozen of signups from China. We got more signups from China in the
past month than from Canada!
One of our core values is the speed of our search engine. To provide a
realtime search experience, we want the response times to be lower than 100ms,
including the round trip to search servers. In this context a low latency is
essential. Up to now we have been able to cover North America and Europe in
less than 100ms (search computation included) but our latency with Asia was
between 200ms and 300ms.
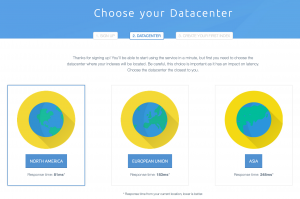
The first step of our on-boarding process is to select the datacenter where
your search engine is hosted (we offer multi-datacenter distribution only for
enterprise users). Interestingly, we discovered that we had no drop for
European & US users but it became significant for others. It was a difficult
choice for people outside of these two regions, or even between the two
datacenters. So we also now display the latency from your browser and pre-
select the "closest" datacenter.
To propose better latency and to reduce friction in the on-boarding process,
it was clear that we had to add a datacenter in Asia. We chose Singapore for
its central location. Unfortunately, the hosting market is very different in
Asia. It's much more expensive to rent servers, so we sadly had to add a
premium on plan prices when choosing this datacenter.
We are very happy to open this new datacenter in Asia with a latency that
reaches our quality standard. Now that Algolia provides realtime search in
Asia, we are even happier to be able to help multinational websites and apps
provide a great search experience to all their users across Europe, North
America & Asia in less than 100ms with our multi-datacenter support!*
Multi-datacenter support is currently only available for Enterprise
accounts.